

Proponents of the Continuous Improvement method often quote the dictum ‘what gets Measured, gets Improved’. I’d like to modify it by adding ‘what gets Monitored…’ to its beginning. Here I’m referring to the Monitoring of the physical assets in their usage conditions and being Measured & Improved for their Reliability (Availability %, Cost $, MTBF, etc.) and Safety metrics.
Traditionally, the feedback loop from the customers about the performance of the product was very slow. It looked like this.

The diagnosis report of the remedy taken will then be saved in a database. Product Engineers, looking to improve design, must pull the information from the field records to understand the reliability issues in the field. This is a time-consuming, highly-resistant, and information-pulled way of understanding field failures. A better way is to monitor the performance of assets using onboard sensors and an IoT framework.
OEMs that have real-time data coming in from their sensors on the fleet are in a prime position to observe issues in the field quickly and take actions to improve reliability faster. Having streaming data gives a peek into the way the product is used, and it drastically reduces the information transfer time from the field. When the asset’s condition is monitored, it can be maintained at the detection of the first anomaly before a catastrophic failure happens.
The framework of using sensor data to observe the asset in real-time and plan maintenance accordingly is called Prognostics & Health Management (PHM). Literature deals with individual use cases extensively.

When you have a small fleet it’s easy to manually monitor all the performance data in real-time and respond to anomalies but when the fleet is in the hundreds, you need some computational support to simplify the GBs of data. Enter Machine Learning into the fray.
Machine Learning (ML) algorithms can analyze historical data from a fleet of assets to create a baseline, to which the fresh data (sensor data) is compared instantaneously to assign a Health Score. Once the health is detected to be of concern then the time remaining for the asset to reach complete failure is computed.
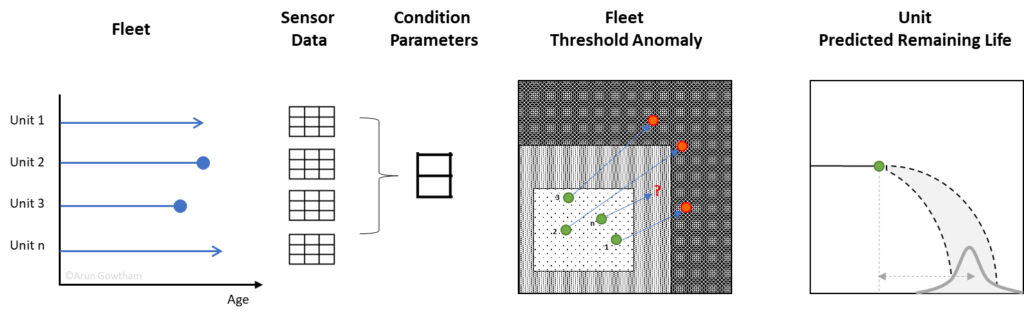
In the next series of articles, I’ll share a step-by-step guide on building a predictive model for a fleet for optimized maintenance.
Related Posts

Step-by-step: How to Implement Predictive Maintenance (PdM)

Only at Scheduled On-Condition Tasks
